Unitree RL GYM
🌎English | 🇨🇳中文
This is a repository for reinforcement learning implementation based on Unitree robots, supporting Unitree Go2, H1, H1_2, and G1.
|
Isaac Gym
|
Mujoco
|
Physical
|
|--- | --- | --- |
| [

](https://oss-global-cdn.unitree.com/static/5bbc5ab1d551407080ca9d58d7bec1c8.mp4) | [
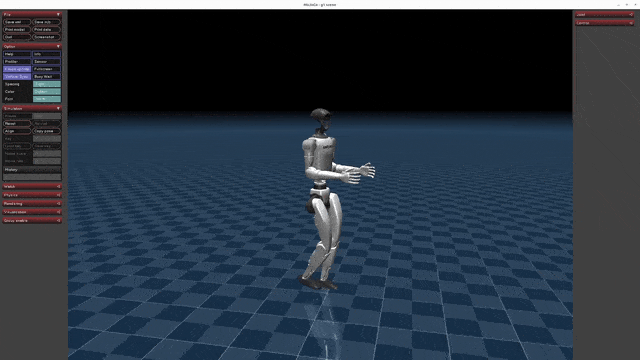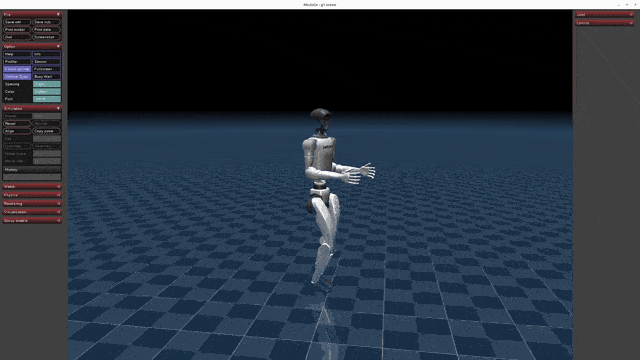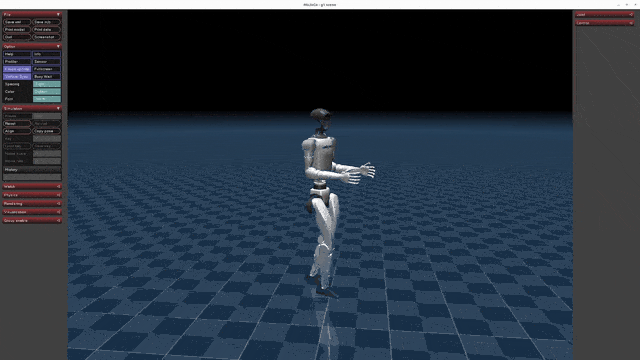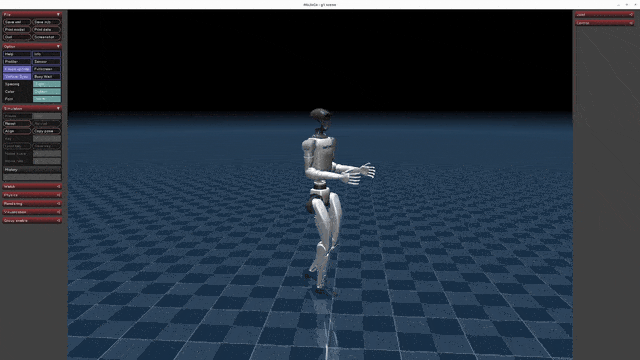
](https://oss-global-cdn.unitree.com/static/5aa48535ffd641e2932c0ba45c8e7854.mp4) | [

](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) |