---
**State-of-the-art machine learning for real-world robotics**
🤗 LeRobot aims to provide models, datasets, and tools for real-world robotics in PyTorch. The goal is to lower the barrier for entry to robotics so that everyone can contribute and benefit from sharing datasets and pretrained models.
🤗 LeRobot contains state-of-the-art approaches that have been shown to transfer to the real-world with a focus on imitation learning and reinforcement learning.
🤗 LeRobot already provides a set of pretrained models, datasets with human collected demonstrations, and simulated environments so that everyone can get started. In the coming weeks, the plan is to add more and more support for real-world robotics on the most affordable and capable robots out there.
🤗 LeRobot hosts pretrained models and datasets on this HuggingFace community page: [huggingface.co/lerobot](https://huggingface.co/lerobot)
#### Examples of pretrained models and environments
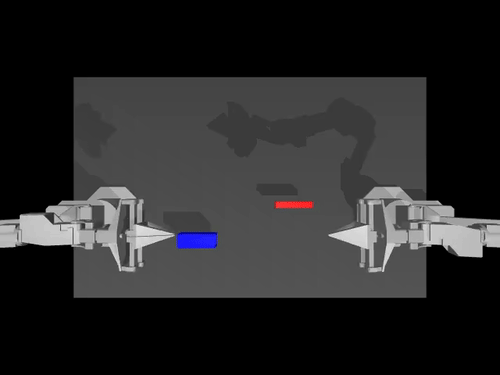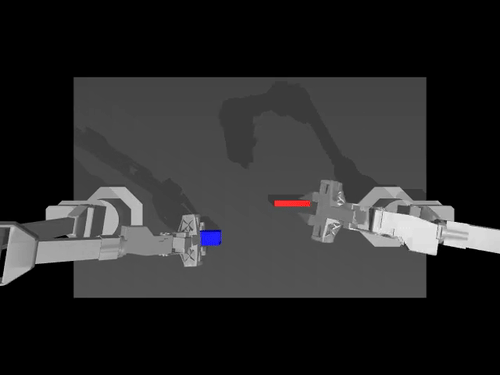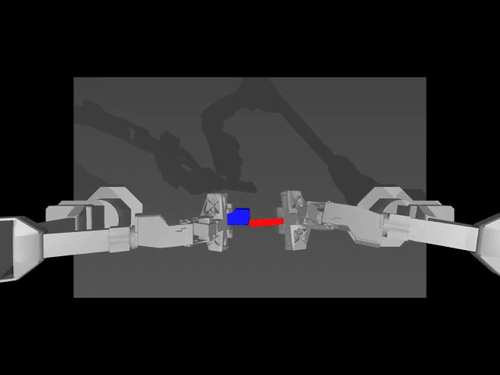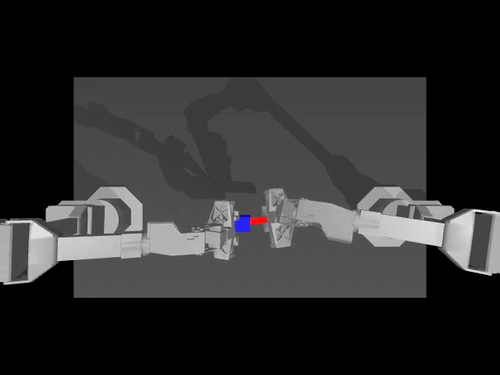
ACT policy on ALOHA env
TDMPC policy on SimXArm env
Diffusion policy on PushT env
### Acknowledgment
- ACT policy and ALOHA environment are adapted from [ALOHA](https://tonyzhaozh.github.io/aloha/)
- Diffusion policy and Pusht environment are adapted from [Diffusion Policy](https://diffusion-policy.cs.columbia.edu/)
- TDMPC policy and Simxarm environment are adapted from [FOWM](https://www.yunhaifeng.com/FOWM/)
- Abstractions and utilities for Reinforcement Learning come from [TorchRL](https://github.com/pytorch/rl)
## Installation
Create a virtual environment with Python 3.10, e.g. using `conda`:
```bash
conda create -y -n lerobot python=3.10
conda activate lerobot
```
[Install `poetry`](https://python-poetry.org/docs/#installation) (if you don't have it already)
```bash
curl -sSL https://install.python-poetry.org | python -
```
Install dependencies
```bash
poetry install
```
If you encounter a disk space error, try to change your tmp dir to a location where you have enough disk space, e.g.
```bash
mkdir ~/tmp
export TMPDIR='~/tmp'
```
To use [Weights and Biases](https://docs.wandb.ai/quickstart) for experiments tracking, log in with
```bash
wandb login
```
## Walkthrough
```
.
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, simxarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, simxarm
| | ├── envs # various sim environments: aloha, pusht, simxarm
| | └── policies # various policies: act, diffusion, tdmpc
| └── scripts # contains functions to execute via command line
| ├── visualize_dataset.py # load a dataset and render its demonstrations
| ├── eval.py # load policy and evaluate it on an environment
| └── train.py # train a policy via imitation learning and/or reinforcement learning
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
├── .github
| └── workflows
| └── test.yml # defines install settings for continuous integration and specifies end-to-end tests
└── tests # contains pytest utilities for continuous integration
```
### Visualize datasets
You can import our dataset class, download the data from the HuggingFace hub and use our rendering utilities:
```python
""" Copy pasted from `examples/1_visualize_dataset.py` """
import lerobot
from lerobot.common.datasets.aloha import AlohaDataset
from torchrl.data.replay_buffers import SamplerWithoutReplacement
from lerobot.scripts.visualize_dataset import render_dataset
print(lerobot.available_datasets)
# >>> ['aloha_sim_insertion_human', 'aloha_sim_insertion_scripted', 'aloha_sim_transfer_cube_human', 'aloha_sim_transfer_cube_scripted', 'pusht', 'xarm_lift_medium']
# we use this sampler to sample 1 frame after the other
sampler = SamplerWithoutReplacement(shuffle=False)
dataset = AlohaDataset("aloha_sim_transfer_cube_human", sampler=sampler)
video_paths = render_dataset(
dataset,
out_dir="outputs/visualize_dataset/example",
max_num_samples=300,
fps=50,
)
print(video_paths)
# >>> ['outputs/visualize_dataset/example/episode_0.mp4']
```
Or you can achieve the same result by executing our script from the command line:
```bash
python lerobot/scripts/visualize_dataset.py \
env=aloha \
task=sim_sim_transfer_cube_human \
hydra.run.dir=outputs/visualize_dataset/example
# >>> ['outputs/visualize_dataset/example/episode_0.mp4']
```
### Evaluate a pretrained policy
You can import our environment class, download pretrained policies from the HuggingFace hub, and use our rollout utilities with rendering:
```python
""" Copy pasted from `examples/2_evaluate_pretrained_policy.py`
# TODO
```
Or you can achieve the same result by executing our script from the command line:
```bash
python lerobot/scripts/eval.py \
--hub-id lerobot/diffusion_policy_pusht_image \
--revision v1.0 \
eval_episodes=10 \
hydra.run.dir=outputs/eval/example_hub
```
After launching training of your own policy, you can also re-evaluate the checkpoints with:
```bash
python lerobot/scripts/eval.py \
--config PATH/TO/FOLDER/config.yaml \
policy.pretrained_model_path=PATH/TO/FOLDER/weights.pth \
eval_episodes=10 \
hydra.run.dir=outputs/eval/example_dir
```
See `python lerobot/scripts/eval.py --help` for more instructions.
### Train your own policy
You can import our dataset, environment, policy classes, and use our training utilities (if some data is missing, it will be automatically downloaded from HuggingFace hub):
```python
""" Copy pasted from `examples/3_train_policy.py`
# TODO
```
Or you can achieve the same result by executing our script from the command line:
```bash
python lerobot/scripts/train.py \
hydra.run.dir=outputs/train/example
```
You can easily train any policy on any environment:
```bash
python lerobot/scripts/train.py \
env=aloha \
task=sim_insertion \
dataset_id=aloha_sim_insertion_scripted \
policy=act \
hydra.run.dir=outputs/train/aloha_act
```
## Contribute
Feel free to open issues and PRs, and to coordinate your efforts with the community on our [Discord Channel](https://discord.gg/VjFz58wn3R). For specific inquiries, reach out to [Remi Cadene](remi.cadene@huggingface.co).
**TODO**
If you are not sure how to contribute or want to know the next features we working on, look on this project page: [LeRobot TODO](https://github.com/orgs/huggingface/projects/46)
**Follow our style**
```bash
# install if needed
pre-commit install
# apply style and linter checks before git commit
pre-commit
```
**Add dependencies**
Instead of `pip install some-package`, we use `poetry` to track the versions of our dependencies:
```bash
poetry add some-package
```
**NOTE:** Currently, to ensure the CI works properly, any new package must also be added in the CPU-only environment dedicated CI. To do this, you should create a separate environment and add the new package there as well. For example:
```bash
# add the new package to your main poetry env
poetry add some-package
# add the same package to the CPU-only env dedicated to CI
conda create -y -n lerobot-ci python=3.10
conda activate lerobot-ci
cd .github/poetry/cpu
poetry add some-package
```
**Run tests locally**
Install [git lfs](https://git-lfs.com/) to retrieve test artifacts (if you don't have it already).
On Mac:
```bash
brew install git-lfs
git lfs install
```
On Ubuntu:
```bash
sudo apt-get install git-lfs
git lfs install
```
Pull artifacts if they're not in [tests/data](tests/data)
```bash
git lfs pull
```
When adding a new dataset, mock it with
```bash
python tests/scripts/mock_dataset.py --in-data-dir data/$DATASET --out-data-dir tests/data/$DATASET
```
Run tests
```bash
DATA_DIR="tests/data" pytest -sx tests
```
**Add a new dataset**
To add a dataset to the hub, first login and use a token generated from [huggingface settings](https://huggingface.co/settings/tokens) with write access:
```bash
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential
```
Then you can upload it to the hub with:
```bash
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli upload $HF_USER/$DATASET data/$DATASET \
--repo-type dataset \
--revision v1.0
```
You will need to set the corresponding version as a default argument in your dataset class:
```python
version: str | None = "v1.0",
```
See: [`lerobot/common/datasets/pusht.py`](https://github.com/Cadene/lerobot/blob/main/lerobot/common/datasets/pusht.py)
For instance, for [lerobot/pusht](https://huggingface.co/datasets/lerobot/pusht), we used:
```bash
HF_USER=lerobot
DATASET=pusht
```
If you want to improve an existing dataset, you can download it locally with:
```bash
mkdir -p data/$DATASET
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download ${HF_USER}/$DATASET \
--repo-type dataset \
--local-dir data/$DATASET \
--local-dir-use-symlinks=False \
--revision v1.0
```
Iterate on your code and dataset with:
```bash
DATA_DIR=data python train.py
```
Upload a new version (v2.0 or v1.1 if the changes are respectively more or less significant):
```bash
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli upload $HF_USER/$DATASET data/$DATASET \
--repo-type dataset \
--revision v1.1 \
--delete "*"
```
Then you will need to set the corresponding version as a default argument in your dataset class:
```python
version: str | None = "v1.1",
```
See: [`lerobot/common/datasets/pusht.py`](https://github.com/Cadene/lerobot/blob/main/lerobot/common/datasets/pusht.py)
Finally, you might want to mock the dataset if you need to update the unit tests as well:
```bash
python tests/scripts/mock_dataset.py --in-data-dir data/$DATASET --out-data-dir tests/data/$DATASET
```
**Add a pretrained policy**
Once you have trained a policy you may upload it to the HuggingFace hub.
Firstly, make sure you have a model repository set up on the hub. The hub ID looks like HF_USER/REPO_NAME.
Secondly, assuming you have trained a policy, you need:
- `config.yaml` which you can get from the `.hydra` directory of your training output folder.
- `model.pt` which should be one of the saved models in the `models` directory of your training output folder (they won't be named `model.pt` but you will need to choose one).
- `stats.pth` which should point to the same file in the dataset directory (found in `data/{dataset_name}`).
To upload these to the hub, prepare a folder with the following structure (you can use symlinks rather than copying):
```
to_upload
├── config.yaml
├── model.pt
└── stats.pth
```
With the folder prepared, run the following with a desired revision ID.
```bash
huggingface-cli upload $HUB_ID to_upload --revision $REVISION_ID
```
If you want this to be the default revision also run the following (don't worry, it won't upload the files again; it will just adjust the file pointers):
```bash
huggingface-cli upload $HUB_ID to_upload
```
See `eval.py` for an example of how a user may use your policy.
**Improve your code with profiling**
An example of a code snippet to profile the evaluation of a policy:
```python
from torch.profiler import profile, record_function, ProfilerActivity
def trace_handler(prof):
prof.export_chrome_trace(f"tmp/trace_schedule_{prof.step_num}.json")
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(
wait=2,
warmup=2,
active=3,
),
on_trace_ready=trace_handler
) as prof:
with record_function("eval_policy"):
for i in range(num_episodes):
prof.step()
# insert code to profile, potentially whole body of eval_policy function
```
```bash
python lerobot/scripts/eval.py \
--config outputs/pusht/.hydra/config.yaml \
pretrained_model_path=outputs/pusht/model.pt \
eval_episodes=7
```